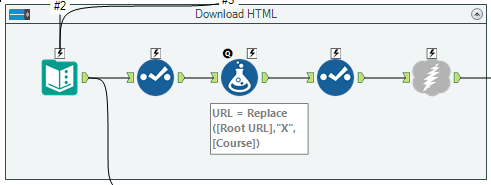
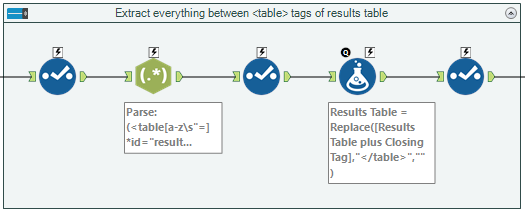
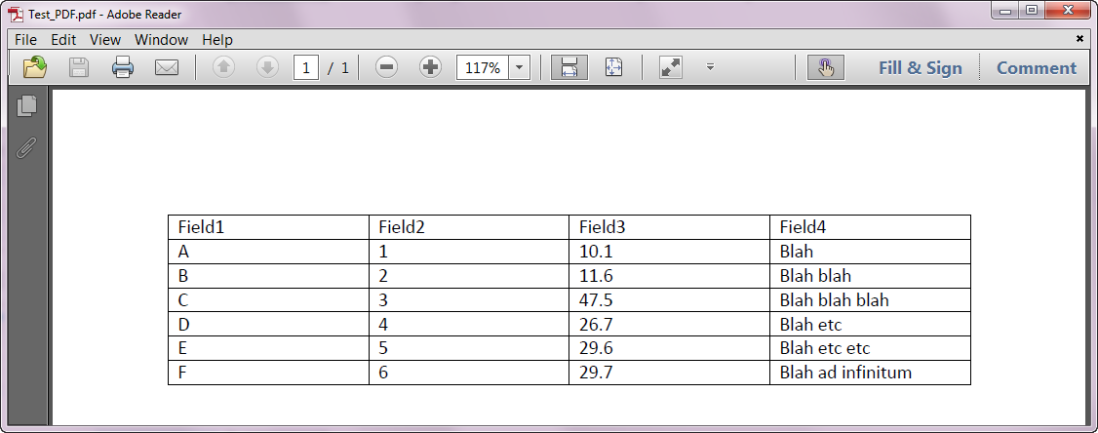
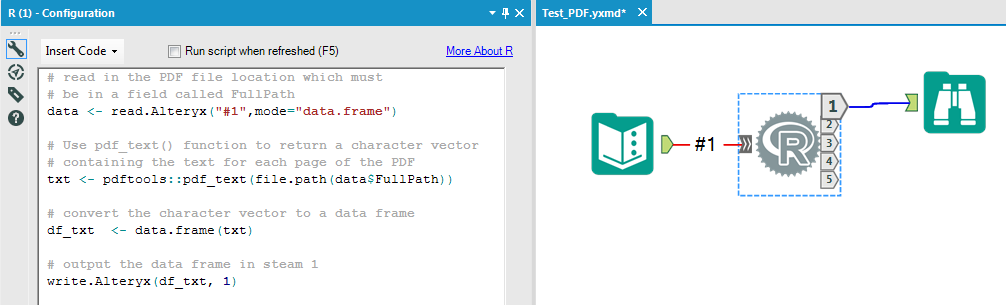
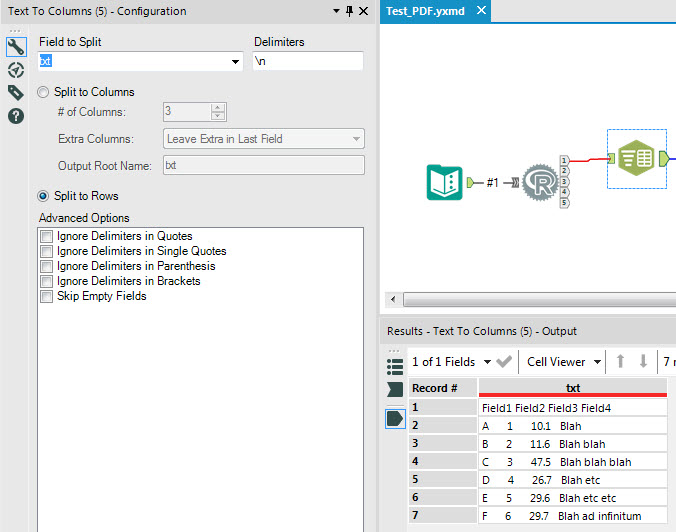
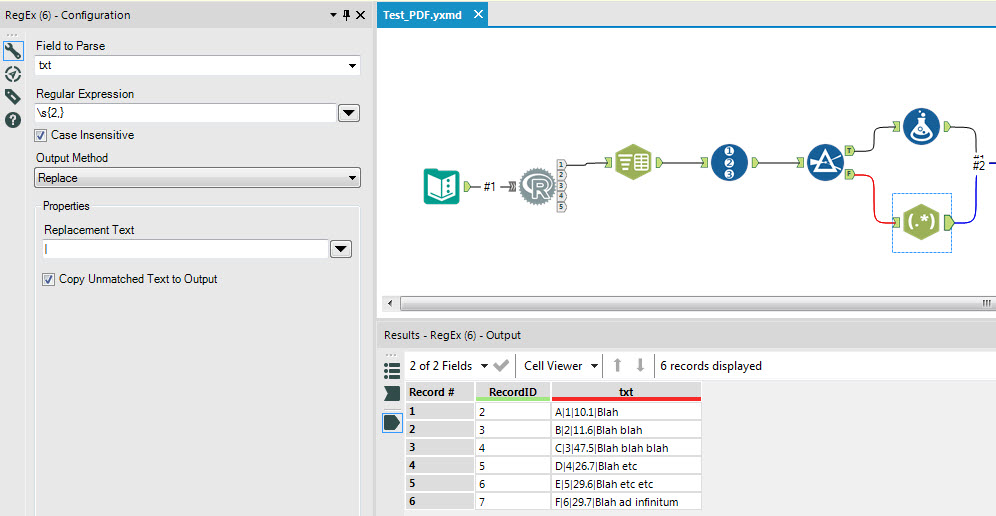
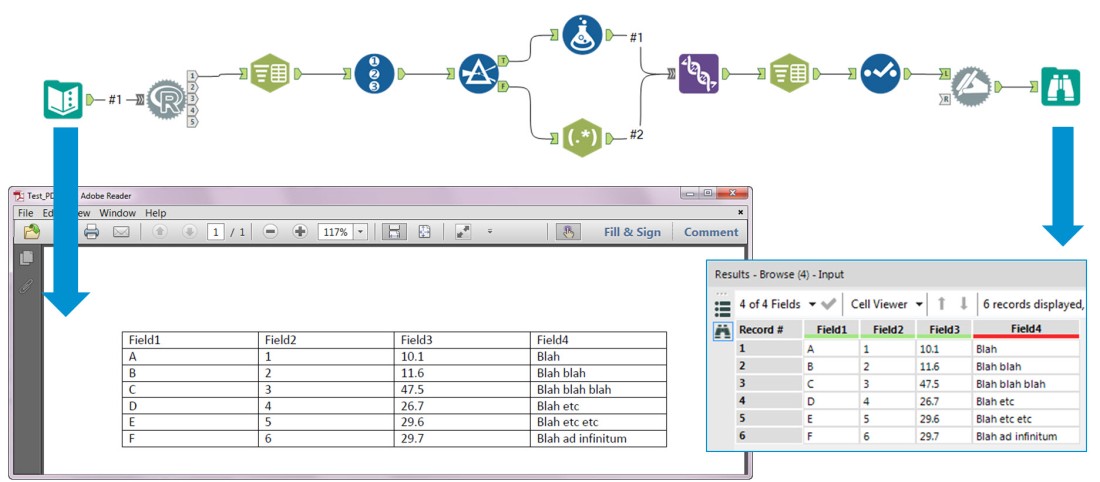
The XACT_STATE function can be used in a CATCH block to decide whether to commit or roll back a transaction.
In the example below, the UPDATE statement raises an error and control is passed to the CATCH block. In the CATCH block, XACT_STATE is used to check that the transaction can be rolled back. In this case, the INSERT statement before the failed UPDATE statement is rolled back and CountyTown remains an empty table.
/* If XACT_ABORT is ON, an error will cause the entire
transaction to be terminated and rolled back. It is
recommended to set XACT_ABORT ON so that command timeouts
won't leave the transaction open. For the purposes of this
post XACT_ABORT is set to OFF to show how XACT_STATE can
be used to commit part of a transaction. */
SET XACT_ABORT OFF
IF OBJECT_ID('CountyTown','U') IS NOT NULL
DROP TABLE CountyTown;
GO
CREATE TABLE CountyTown
(
[County] NVARCHAR(10)
,[Town] NVARCHAR(10)
);
GO
BEGIN TRY
BEGIN TRANSACTION;
/* succeeds */
INSERT INTO CountyTown VALUES
(N'Tipperary',N'Clonmel')
,(N'Clare',N'Ennis');
/* fails - error occurs */
UPDATE CountyTown
SET [County] = N'This string is too long';
/* does not execute as control is
passed to CATCH block */
INSERT INTO CountyTown VALUES
(N'Kerry',N'Tralee');
/* would commit the transaction if
an error did not occur */
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
/* rolls back the transaction
if this is possible (i.e. if XACT_STATE is
not equal to 0) */
IF XACT_STATE() 0
BEGIN
PRINT N'Error encountered'
PRINT N'Error Msg: '+ERROR_MESSAGE()+N' Line: '
+CAST(ERROR_LINE() AS NVARCHAR(10))
PRINT N'Rolling back transaction'
ROLLBACK TRANSACTION;
END
END CATCH
GO
In the following example, XACT_STATE is used to commit the statements that executed before the error occurred; that is, the first INSERT statement is committed and the table CountyTown will contain 2 rows:
| County |
Town |
| Tipperary |
Clonmel |
| Clare |
Ennis |
/* If XACT_ABORT is ON, an error will cause the entire
transaction to be terminated and rolled back. It is
recommended to set XACT_ABORT ON so that command timeouts
won't leave the transaction open. For the purposes of this
post XACT_ABORT is set to OFF to show how XACT_STATE can
be used to commit part of a transaction. */
SET XACT_ABORT OFF
IF OBJECT_ID('CountyTown','U') IS NOT NULL
DROP TABLE CountyTown;
GO
CREATE TABLE CountyTown
(
[County] NVARCHAR(10)
,[Town] NVARCHAR(10)
);
GO
BEGIN TRY
BEGIN TRANSACTION;
/* succeeds */
INSERT INTO CountyTown VALUES
(N'Tipperary',N'Clonmel')
,(N'Clare',N'Ennis');
/* fails - error occurs */
UPDATE CountyTown
SET [County] = N'This string is too long';
/* does not execute as control is
passed to CATCH block */
INSERT INTO CountyTown VALUES
(N'Kerry',N'Tralee');
/* would commit the transaction if
an error did not occur */
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
/* rolls back transaction
if transaction is uncommittable */
IF XACT_STATE() = -1
BEGIN
PRINT N'Error encountered'
PRINT N'Error Msg: '+ERROR_MESSAGE()+N' Line: '
+CAST(ERROR_LINE() AS NVARCHAR(10))
PRINT N'Rolling back transaction'
ROLLBACK TRANSACTION;
END
/* commits the transaction
if transaction is committable */
IF XACT_STATE() = 1
BEGIN
PRINT N'Error encountered'
PRINT N'Error Msg: '+ERROR_MESSAGE()+N' Line: '
+CAST(ERROR_LINE() AS NVARCHAR(10))
PRINT N'Committing transaction'
COMMIT TRANSACTION;
END
END CATCH
GO