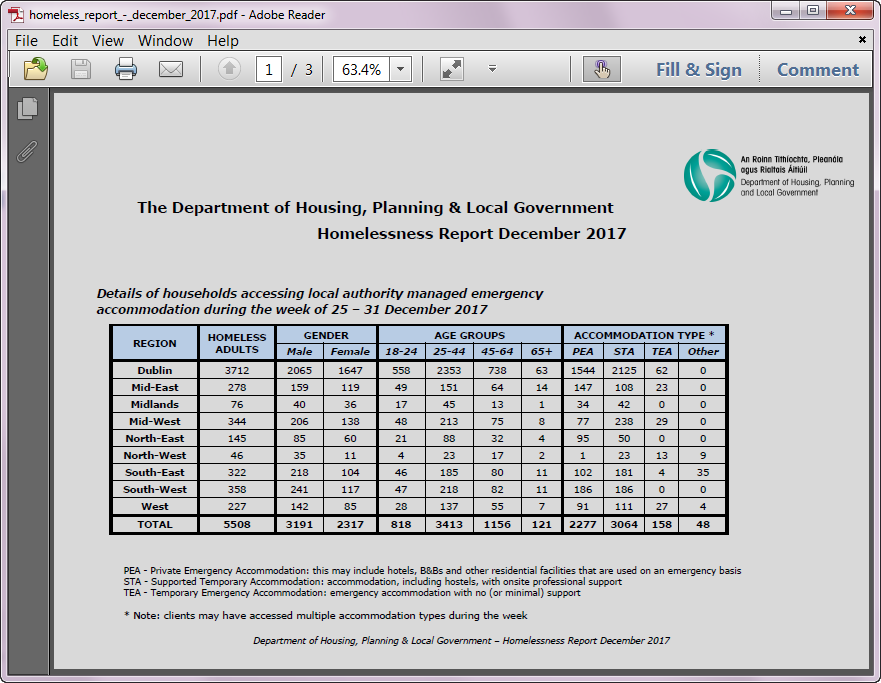
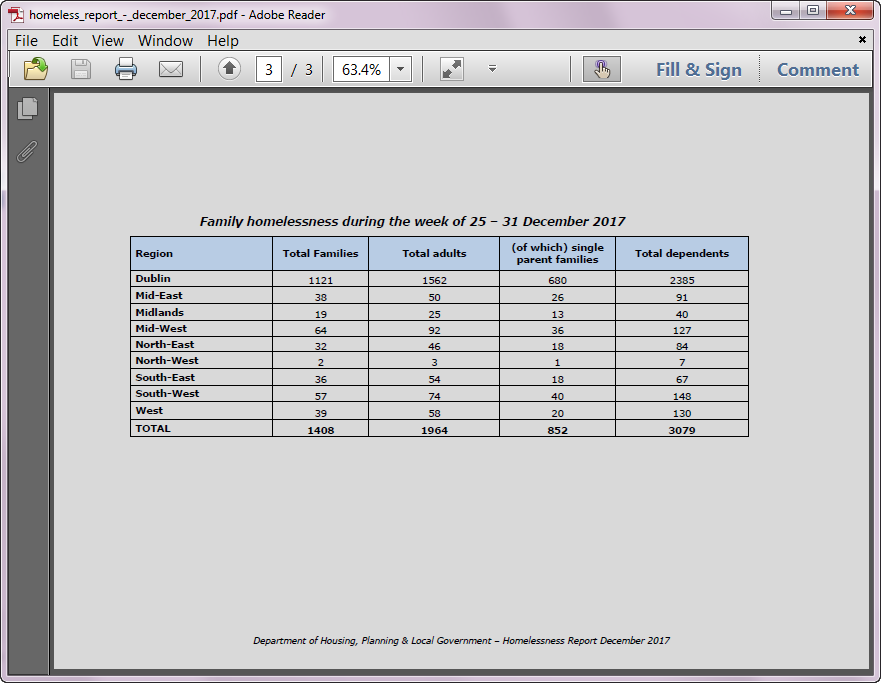
The Dept. of Housing publishes a PDF report every month on the number of people accessing emergency accommodation in Ireland. The report contains 2 main tables: one based on adults and one based on families.
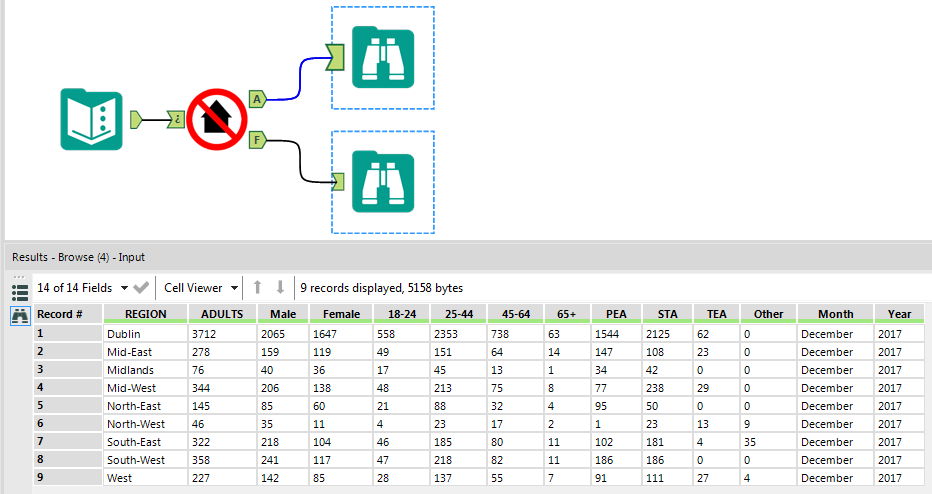
An Alteryx macro which extracts these 2 tables was built. The macro takes the full path of the PDF as an input and has 2 outputs: one for the adults table and one for the families table.
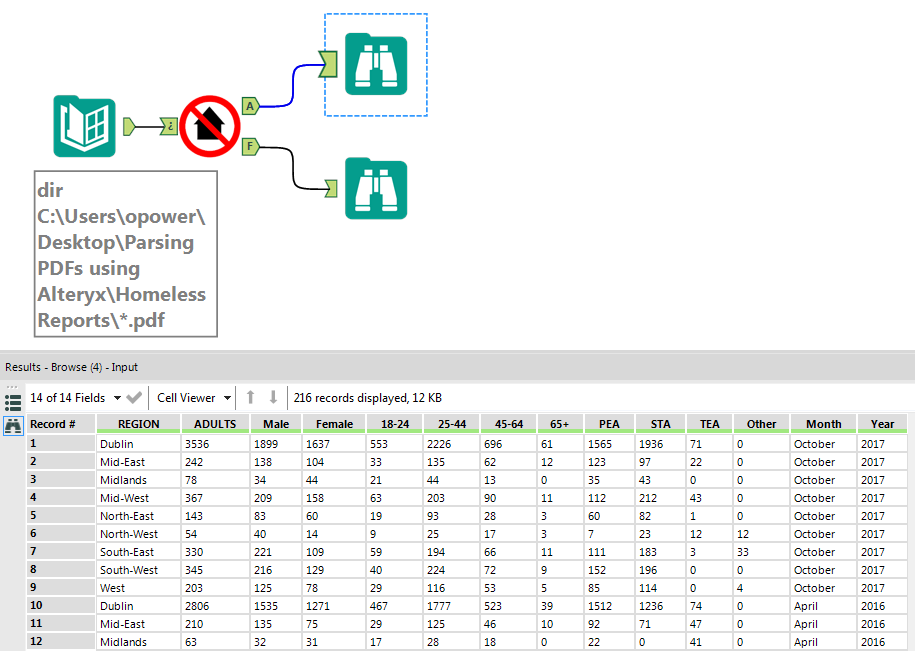
This macro is actually a batch macro which means it can be fed a list of PDFs to parse. The Directory tool is used to generate this list by pointing it at the folder in which all the monthly reports are saved.
A Tableau dashboard was then built to display the data extracted from 2 years of monthly reports. The dashboard can be viewed here on Tableau Public.

The batch macro which extracts the tables from the report has the following steps:
1. Extract the text from the PDF using the R tool and the R package pdftools. The output of this step is a single string for each page of the PDF.
2. Flag the pages containing the tables. This is based on knowing the titles of the tables.
3. For these pages, split the string into rows at the \n delimiter using the Text to Columns tool.
4. Isolate the rows that correspond to rows of the tables (and not titles or footers).
5. Use the Regex tool to replace spaces by pipes (|) and then use the Text to Columns tool to split the strings at the | delimiter.
My previous post covers this in more detail: Parsing PDFs using Alteryx (and a little R)
Month: February 2018
Parsing PDFs using Alteryx (and a little R)
Motivation
Suppose we have a PDF which contains a table and we would like to extract that table.
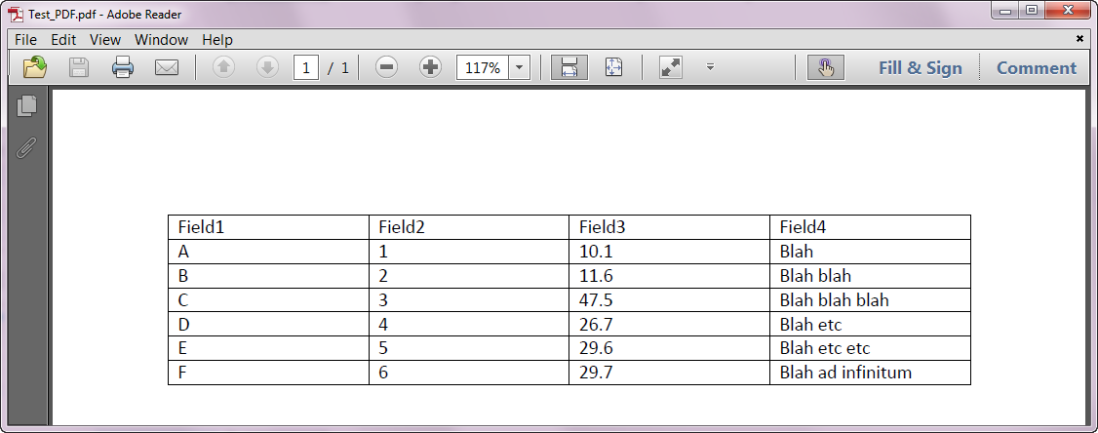
The R package pdftools can extract text from PDFs, and Alteryx, which is a visually intuitive drag-and-drop data analysis tool, makes it very easy for R novices to include R code snippets as part of a workflow.
Step-by-step guide
In order to build an Alteryx workflow which can extract text from PDFs, first install the packages pdftools and Rcpp. To do this, right-click on the R version which installed with Alteryx and select “Run as administrator”.
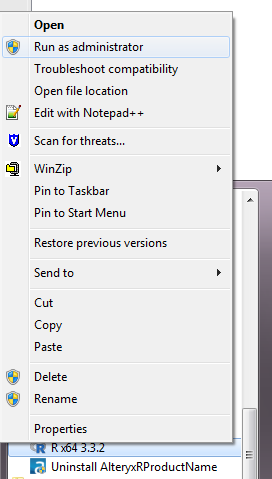
Now run the commands below to install/update the required packages.
install.packages(“Rcpp”) install.packages(“pdftools”)
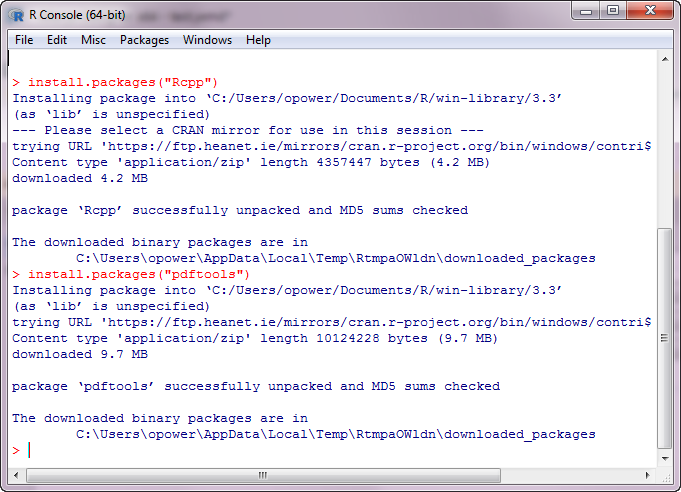
The Alteryx workflow starts with a Text Input tool which contains the full path of the PDF file.
Next the R tool is used to extract the text from the PDF. The code used in the R tool is below.
# read in the PDF file location which must
# be in a field called FullPath
data <- read.Alteryx("#1",mode="data.frame")
# Use pdf_text() function to return a character vector
# containing the text for each page of the PDF
txt <- pdftools::pdf_text(file.path(data$FullPath))
# convert the character vector to a data frame
df_txt <- data.frame(txt)
# output the data frame in steam 1
write.Alteryx(df_txt, 1)
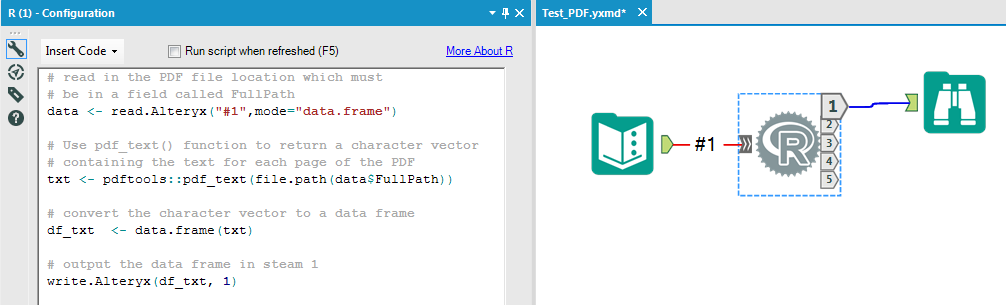
The output from the R tool is a single string which contains the extracted text. To parse this string, use the Text to Columns tool in Alteryx to split the string into rows at the newline (\n) character.
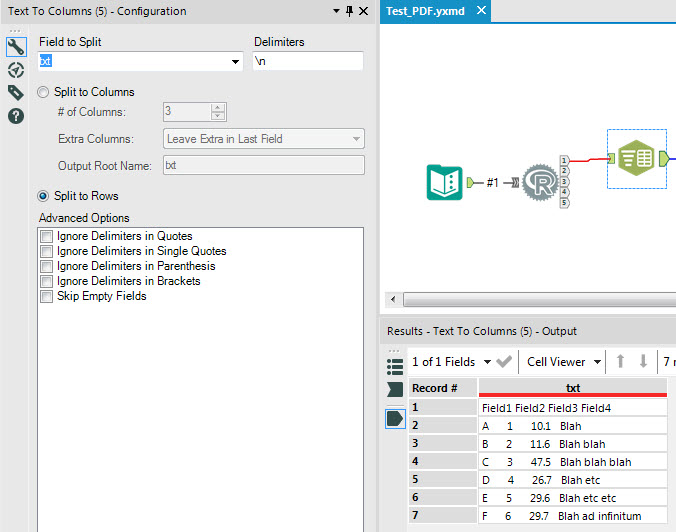
To split out the table columns, use the Regex tool to replace sequences of 2 or more blanks by a pipe delimiter (|).
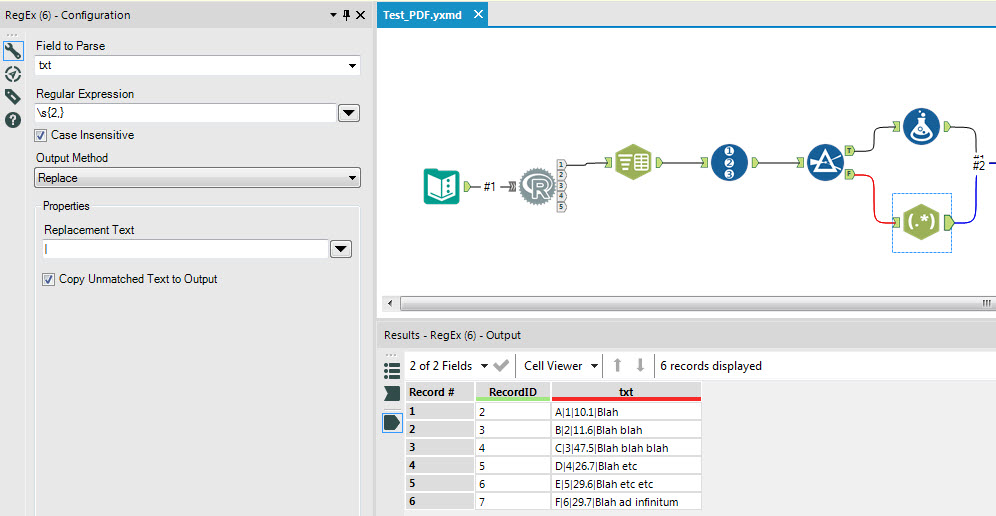
Finally use the Text to Columns tool to split the strings at the pipe delimiter and use the Dynamic Rename tool to take the column names from the first row.
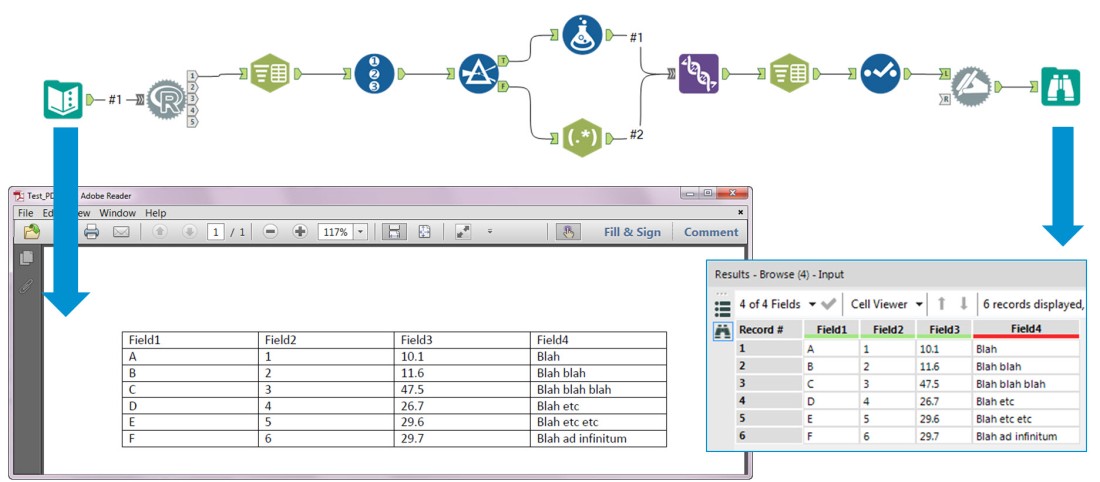
Reference
Alteryx Community | PDF Parsing in Alteryx using R
